News extraction process through scraping at Diario La Discusión
Scraping system to extract news, links, and content from the Diario La Discusión.
Last Test of the Script - 03 / 03 / 2022
This script is a data extractor (scraping), in this case, I extracted the content from the newspaper https://www.ladiscusion.cl, which is a newspaper from my city. This scraping is divided into two parts:
Before starting, we check robots.txt and verify the permissions granted by the newspaper.
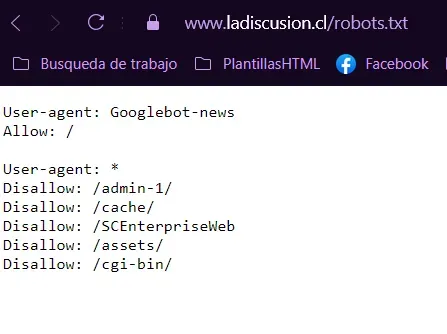
Once ready, we continue.
First Step - Extraction and Creation of DataFrames with News Links by Category from the Navigation Bar.
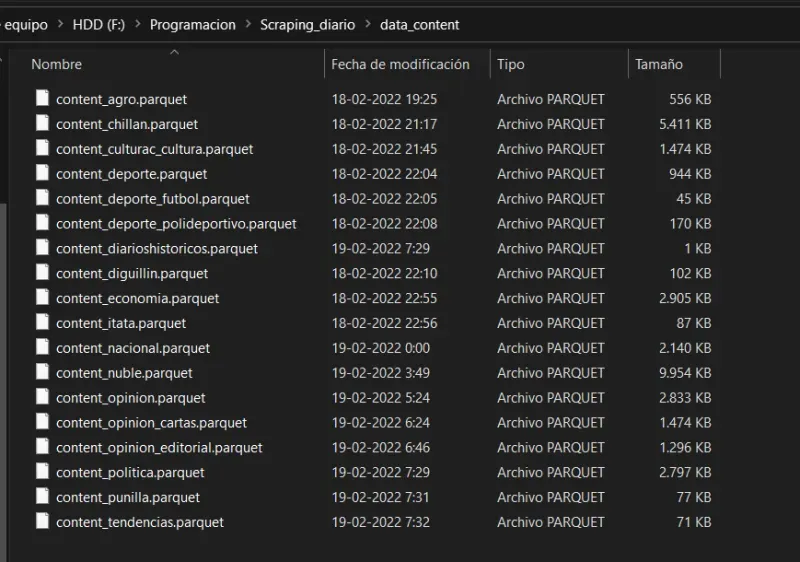
The script creates two folders, data and data_content. In the data folder, categories with links will be stored in a DataFrame, and in data_content, the content will be stored.
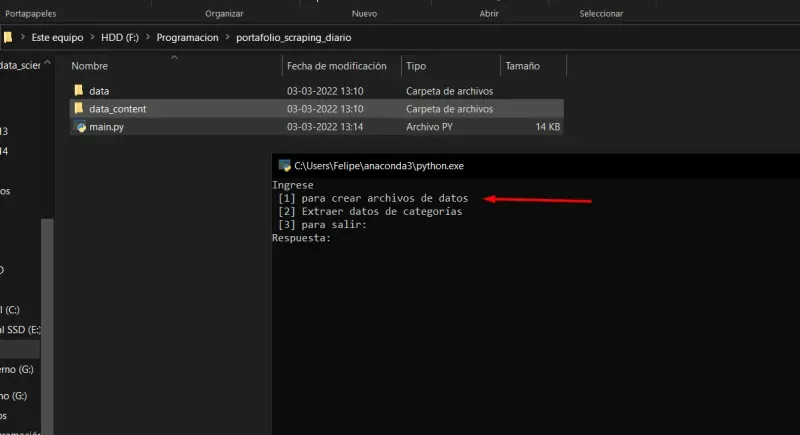
The first step to use the script is to select the first option:
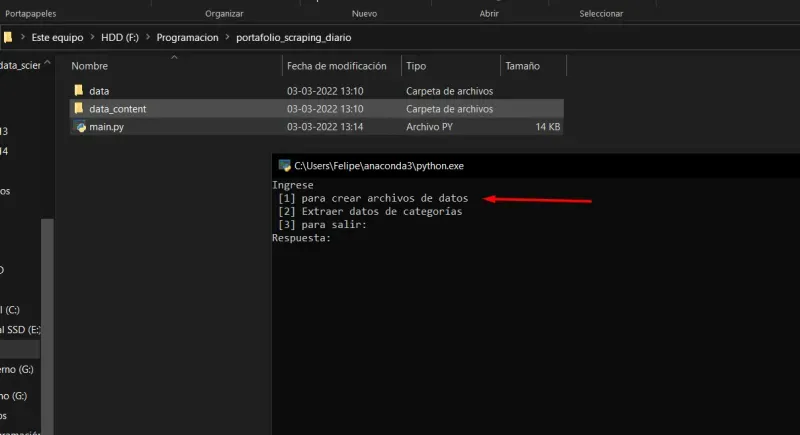
- Once the command [1] is entered, the following will appear:
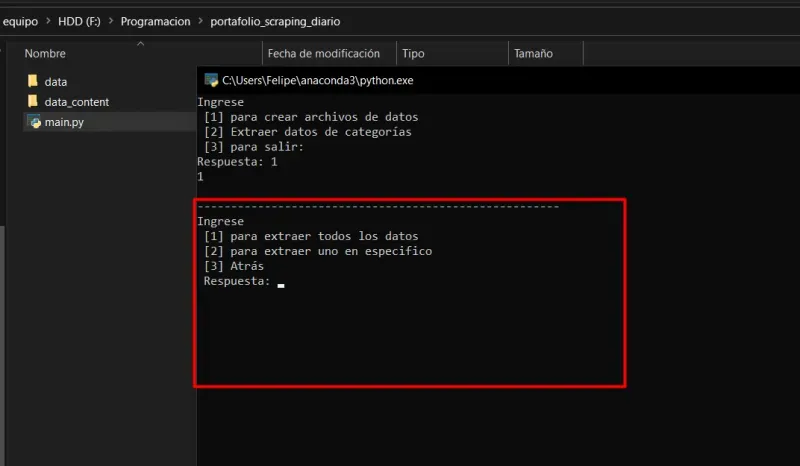
If command 1 is entered, it will start scraping all the links from the navigation bar.
However, option 2 allows us to scrape only the data we want. For demonstration, I will show images of option 2.
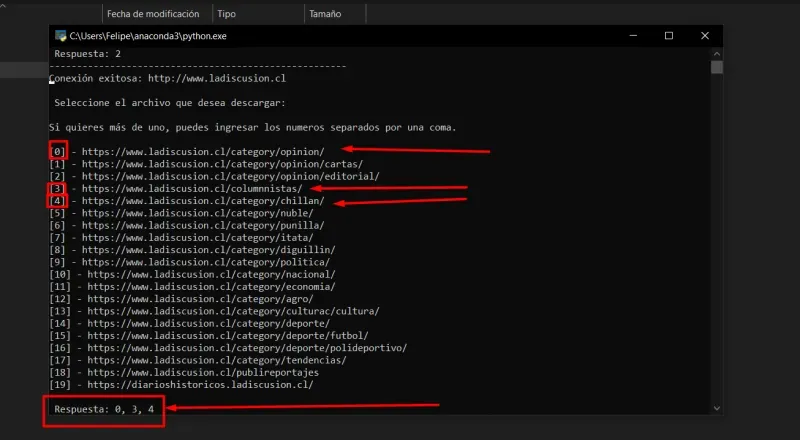
- In the previous case, I entered that I only want 0, 3, and 4. I then ran the code, and it started generating the tables.
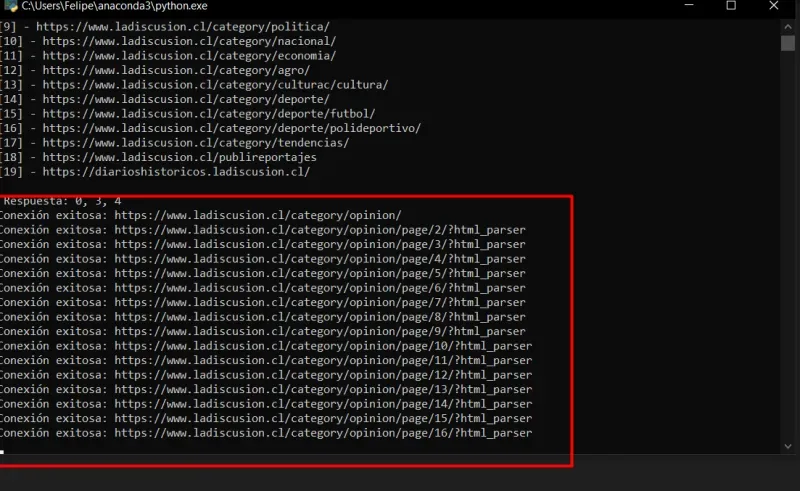
Once the first process is completed.
- We will have the data folder with the DataFrames.
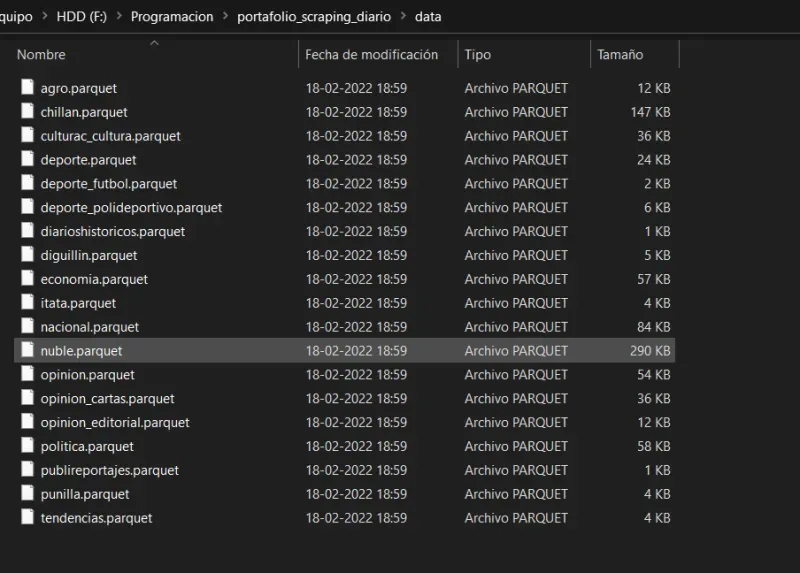
- Here is a glimpse of the first DataFrame.
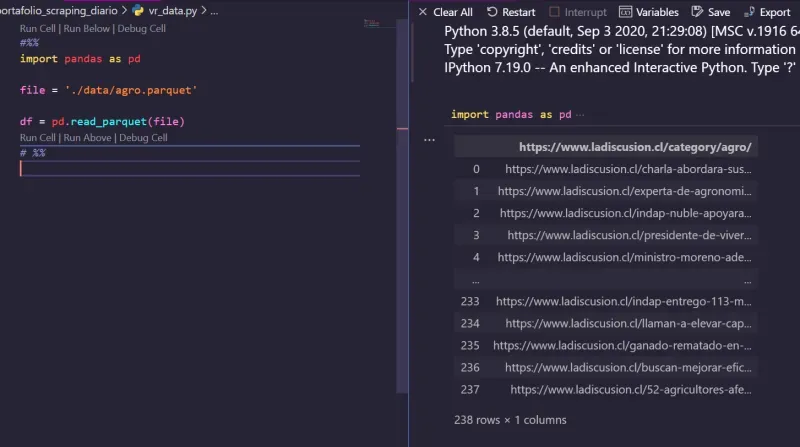
Second Step - Creation of DataFrames with Title - Time - Content - Subtitles
- With the first step, we will have all the news links from the page that were available at the time of executing the script.
- The next step is simple.
- In the script menu, there is option [2].
- This option displays another menu, which will use all the links found in the files in the data folder.
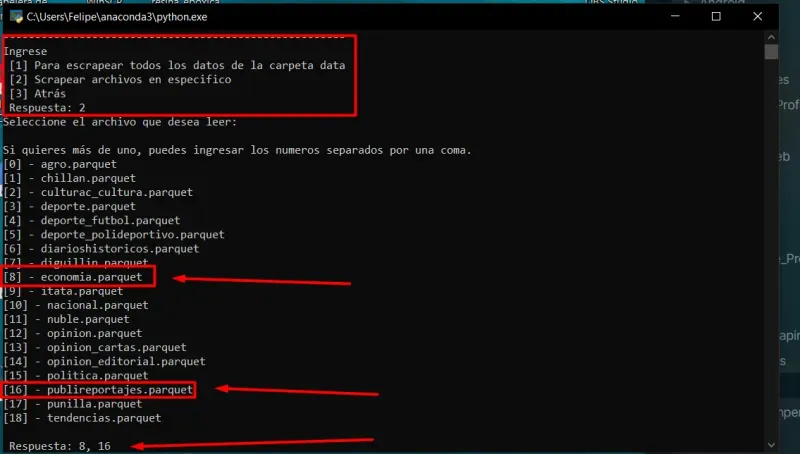
- Option [1] to process all of them.
- Option [2] to scrape specific files.
- I will use option two as a test.
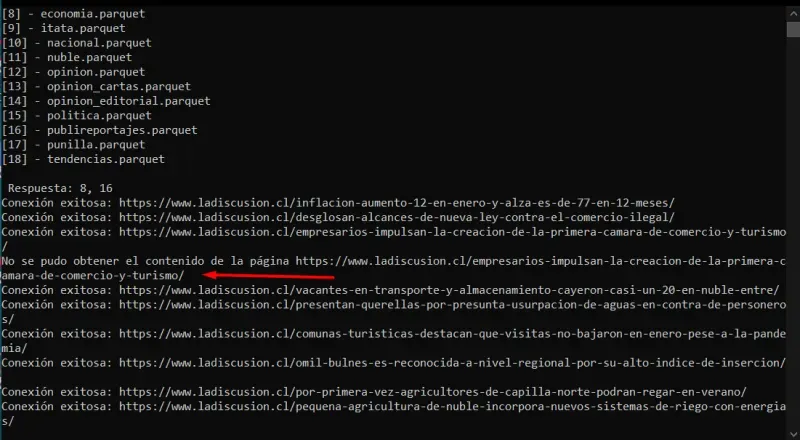
- We can observe that some links cannot be opened; however, the script continues.
- Once finished, in our data_content folder, we will have the DataFrames and content ready for manipulation.
We will look at the first one as an example of a DataFrame.
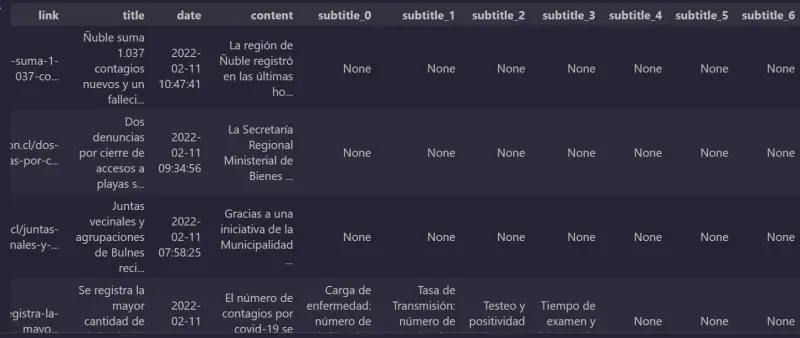
The
df.info()as well.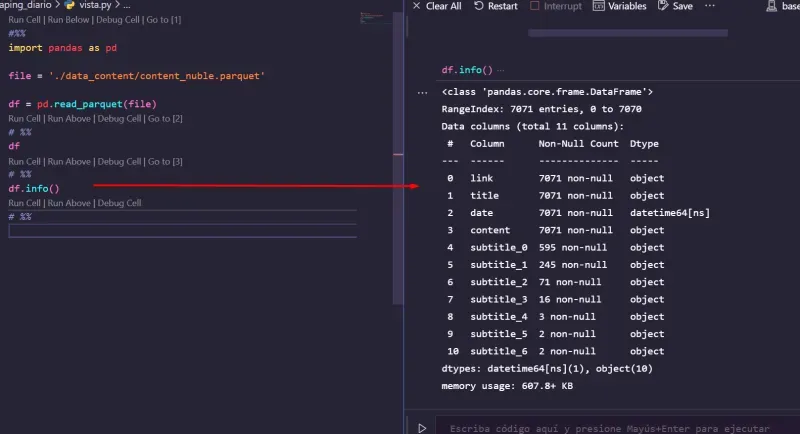
Duration of the Scraping
- 40 minutes, First part.
- 10 hours, Second part.
Aspects to Optimize
- Threads can be used to reduce scraping time by scraping in parallel.
- Files that did not receive a GET request can be captured for independent scraping.